

ESPECIFICACIÓN DEL SISTEMA
 |
Introducción |
En esta introducción vamos a tratar de explicar algunos de los conceptos básicos, sobre los que se va a asentar, la modelización en el ámbito teórico del Sistema Operativo Zeus 98. Es importante que estén bien claros y sean comprendidos, para asimilar el propósito del proyecto.
El conjunto de definiciones que se exponen, van a dar una idea somera de lo real, pero van a dejar claro el concepto principal, y a lo largo del desarrollo, se podrá llegar a una comprensión mayor y más compleja de lo que realmente se quiere decir. Empecemos pues.
Definiciones básicas.
Sistema Operativo.
Es generalmente un software, que ponen en contacto al usuario con los recursos del hardware de la máquina, incluyendo los periféricos que lleve ligados a ella. Al referirse al hardware de la máquina nos referimos tanto, a lo que éste pueda almacenar, si es su cometido, o con lo que pueda trabajar, o en general haciendo uso específico de la función que le caracteriza, haciendo más fácil el manejo de dicha máquina, y haciéndola transparente al usuario, en vista a su funcionamiento a escala eléctrica, electrónica...
Recurso.
Cualquier servicio de los que dispone la máquina, tanto físicos como lógicos, que se pueden administrar, es decir repartir y reclamar por el sistema operativo, a los diferentes procesos que cohabitan en él.
El recurso puede ser clasificado por diferentes características, una de las más importantes, es la duración que supone una asignación y uso del recurso. Como ejemplos podemos poner:
- En un disco duro, una vez grabada la información, permanece hasta que se elimina a propósito, o salvo un fallo mecánico.
- En la memoria RAM, los datos perduran hasta que no se eliminan, voluntaria o involuntariamente, o bien hasta que apagamos la máquina.
- En una impresora, la información que se quiere plasmar en papel, está presente en su buffer, si lo tiene, hasta que se pasa a papel, tras lo cual desaparece...
|
Procesos |
En esta sección se van a definir tanto los tipos básicos de procesos, que se va a encontrar dentro del Sistema Operativo Zeus 98, como su forma de trabajo. Vamos a especificar en principio los modelos básicos de procesos, para asentar así las bases de una buena comprensión, y lograr una fácil comprensión de la funcionalidad del sistema.
Tipos de procesos.
Atendiendo al modo de trabajo o desempeño dentro del sistema, podemos llevar a cabo una diferenciación de los procesos, en dos amplios grupos:
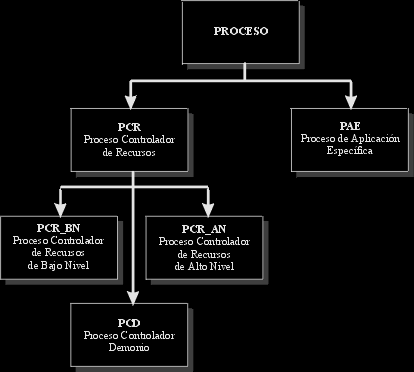
Procesos controladores de recursos (PCR).
Estos procesos están asociados a un recurso del que disponga la máquina. Sólo este proceso controlador tendrá acceso a este recurso, y por lo tanto sólo él lo podrá administrarlo. De manera que si algún proceso necesita tener acceso, a dicho recurso del sistema, deberá llevar a cabo la petición pertinente al administrador del recurso, y esperar la respuesta de éste si fuera necesaria, para actuar sobre él. Dicho esto, resta comentar que necesariamente, los procesos de este tipo van a soportar al menos dos llamadas, y éstas dos son obligatorias, que son DAR_RECURSO_A_PROCESO, en respuesta a la petición de recurso de un proceso al PCR, y DEVOLVER_RECURSO_A_SISTEMA, como devolución de un recurso al sistema por parte de un proceso, una vez que lo ha consumido, ha terminado de trabajar con él o termina la vida de dicho proceso.
Al llevar a cabo este modo de trabajo, aseguramos que ningún proceso acceda al recurso que administra el controlador, dejándolo copado o bloqueado, frente a otros procesos, teniendo todos los procesos, un acceso equitativo sobre los recursos del sistema. Cierto es, que si acontece un fallo cualquiera sobre controlador, y se viene abajo, el recurso que administra se queda inaccesible a todos los procesos. Pero siempre de esta manera, se puede recargar una copia del controlador una vez que se ha caído el anterior, desbloqueando inmediatamente el recurso.
Otra de las grandes ventajas de llevar a cabo el acceso a recursos por módulos, es que para un mismo tipo de recurso (memoria, disco, base de datos...), si se puede acceder de varias maneras diferentes, se pueden crear diferentes controladores que accedan a ese recurso de una manera específica, haciendo totalmente transparente al usuario el acceso al sistema.
Dentro de los PCR, y dependiendo de la naturaleza del recurso que administra, se podrá hacer una doble partición de éstos:
- PCR de bajo nivel.
- PCR de alto nivel.
PCR de bajo nivel (PCR_BN)
Los PCR_BN, son procesos que acceden directamente a los recursos hardware de la máquina, ya sean los diferentes circuitos específicos de la CPU, puertos de las tarjetas de expansión, de los diversos dispositivos de almacenamiento y de entrada / salida, pero también todo lo que sería periféricos externos, como otras unidades de almacenamiento externas, impresoras, plotters... por lo tanto son necesarios.
Como característica especial de los PCR_BN, es necesario decir que son módulos totalmente independientes, y no necesitan el uso de otros módulos de tipo PCR, en la medida de lo posible, ya que se ciñen al reparto del recurso al que están ligados. Dadas estas premisas, obviamente se puede decir que un PCR_BN, no cumple estrictamente las normas establecidas. Esto es así, ya que como procesos que activan la vida del sistema y lo hacen funcionar, y por lo tanto, deben estar presentes de una manera obligada, el mantener entre ellos un protocolo de comunicación, podría sobrecargar el sistema, quitando tiempo de ejecución a los procesos de aplicación. También hay que decir que las funciones no propias del PCR_BN, con respecto al dispositivo que administran, son un grupo reducido, cuya función es ayudar a ubicarse en memoria para comenzar su ejecución, y por lo tanto arrancar el sistema. Es por ello, que este pequeño salto en el planteamiento sea cumplido. Pero también hay que decir que si tiene que soportar una serie de llamadas no propias de su función administradora (enmascaradas), cuya función es la misma en todos los PCR’S que se creen, pueden estar normalizadas.
Al tener un acceso directo sobre el espacio físico de la máquina, tiene que ser capaz de solventar los errores que se puedan producir en la medida de lo posible, y en el caso que no lo sea, deberá provocar una excepción que tendrá que ser tratada mediante una serie de mecanismos desarrollados, para resolver los errores de una manera eficaz o dar constancia de ellos.
PCR de alto nivel (PCR_AN)
Los PCR_AN, son procesos que también acceden a los recursos de la máquina, pero no a los de tipo hardware, sino a los de tipo lógico o software. Se pueden poner muchos ejemplos, pero dos de los más claros sobre los que puede comprender más claramente la filosofía de los PCR_AN, sería por ejemplo, sistemas gestores de bases de datos o bien de los servidores WEB, siendo la base de datos o la WEB, respectivamente, los recursos a administrar. Decimos que son de alto nivel, porque estos procesos si que pueden hacer llamadas no enmascaradas a otros PCR de alto o bajo nivel para llevar a cabo la gestión de su administración. Estos al contrario que los PCR_BN, son opcionales dentro del sistema.
Estos PCR, serán pues muy específicos, pero facilitan los accesos a recursos, permitiendo la concurrencia de procesos diferentes a un mismo recurso, ya que en vez de acceder múltiples procesos a un recurso, por ejemplo sobre un fichero con los consiguientes bloqueos que puede generar cada proceso sobre dicho fichero, los accesos los hace únicamente este proceso, y al tenerlo abierto él sólo no hay problemas de exclusión, generando una gran estabilidad al sistema.
Los errores que puedan acaecer dentro de uno de estos PCR, deberán ser contemplados dentro del mismo PCR_AN, ya que al ser un módulo que realmente trabajará sobre un recurso software, sólo la persona, o grupo de trabajo, que desarrolla la solución, es consciente de los fallos que pueden acontecer durante su ejecución. Por lo tanto estas mismas personas deben suministrar los mecanismos necesarios de corrección de errores y además las respuestas necesarias, para saber en que tipo de error ha incurrido el PCR_AN, y poderlos tratar por el cliente.
Procesos controladores demonios (PCD).
Los PCD, son pequeños programas, que por necesidad, deben de consumir pocos recursos y ser muy rápidos. Ejecutan unas tareas muy específicas e incluso críticas para el sistema. Están englobados en este apartado, porque son necesarios para el buen funcionamiento del sistema operativo, pero no se les puede calificar de PCR, ya que no actúan sobre ningún tipo recurso, n i físico ni lógico. Además son transparentes al usuario y casi incluso al sistema en todo momento, trabajando de una manera encubierta, es decir en segundo plano.
Un buen ejemplo de este tipo de proceso, sería un demonio de mensajería, el cual se dedicaría a recoger mensajes de cualquier tipo de proceso, y mandarlo al destino especificado dentro del mismo mensaje. De esta manera no está accediendo a ningún recurso físico ni lógico, simplemente está a la escucha y realiza una tarea encomendada.
Con respecto al tratamiento de errores debería estar libre de ellos. En el caso de que los haya, serán de tipo lógico, y deberán tratarse como los de los PCR_AN, con la diferencia, de que el cliente al que hay que remitir el error no es cualquier proceso, sino el mismo sistema operativo.
Procesos de aplicación específica (PAE).
En los procesos de aplicación específica, se pueden abarcar todos los demás procesos que no son PCR, que no ayudan al mantenimiento del sistema -con esto no queremos decir que sean perjudiciales, sino que, si no están presentes el sistema no se se ve alterado en su funcionamiento por defecto -, y que generalmente, va a ayudar al usuario a llevar a cabo un conjunto de tareas que le facilitan su trabajo, comunicación, entretenimiento...
Los PAE, dependen integralmente de los PCR, máximo si se trata de los PCR_BN, ya que son los que le van a dar los recursos necesarios, para que el proceso de aplicación pueda desempeñar la tarea para la cual ha sido diseñado. Ellos no pueden hacer llamadas vía directa al hardware del sistema, sino a través del PCR. Si se desea pueden implementar internamente una serie de funciones a las que puede responder, e instaurar un protocolo de comunicación para servirlas a otros procesos, en este caso estaría más cerca de un PCR_AN.
Otro factor importante que los diferencia de los PCR, es que este tipo de procesos pueden tener asignado una pantalla y un teclado propios del proceso, que es una entrada / salida (E/S), vía teclado / monitor compartidos, personalizado para cada proceso, aunque también se puede dar el caso de que no le haga falta, y por lo tanto no se le asigne. Los PCR normalmente no dispondrán de ella, y si necesita de ella en casos excepcionales, será la salida de errores, que es una salida 100% vídeo, a la que puedan recurrir.
Los errores serán contemplados por la persona o grupo de personas que desarrollen la aplicación, realizando su tratamiento a alto nivel, y dejando en última instancia que los resuelva el sistema operativo. Además deberían de proporcionar una serie de códigos de salida de la aplicación, para saber el buen o mal funcionamiento de ella. Obviamente, al depender de la persona que desarrolla la aplicación, todo el posible tratamiento de errores es opcional.
Recapitulación de características de los procesos.
Tras ver las características de los procesos divididas por función que realizan dentro del sistema operativo, vamos a exponer de manera concisa las funciones que deben llevar a cabo:
Características de los PCR_BN.
Tipos de procesos.
Características de los PCR_AN.
Características de los PCD.
Características de los PAE.
Servidores de función generalizada (SFG).
Vamos a denominar Servidor de Función Generalizada, a un único PCR o conjunto de PCR, que administran un mismo recurso, pero acceden a él de diferente manera. Al definirlo así esta un tanto confuso, pero realmente es muy fácil de comprender. Nos basamos, en que por el avance tecnológico, una mayor especialización, o para sacar un rendimiento mayor a ciertos dispositivos, los periféricos se llegan a tratar lógicamente de una manera diferente en distintos sistemas, aunque físicamente sea el mismo.
Vamos a exponer un ejemplo claro y muy vigente. En el disco duro de nuestro ordenador tenemos varias particiones, realizadas por diferentes sistemas operativos. Es posible que de esta manera, tengamos ciertas ventajas, que en esta explicación no vienen al caso, pero lo cierto es que, es posible que desde una partición no se pueda acceder a otra, ya que por lo general no son compatibles los tipos de FAT, y mediante alguno de los sistemas operativos residentes en la máquina, por lo tanto, no podamos acceder a los datos de otras regiones del disco. Si tenemos la típica FAT16, en una partición, en otra una NTFS y en una tercera una nativa de Linux, se podrían implementar tres PCR_BN que supiesen administrar cada uno de los tipos de particiones. Además como vemos, están actuando sobre un mismo dispositivo físico, pero acceden a él de diferente manera. Por eso para este sistema de ejemplo el Servidor de Disco Generalizado estaría compuesto por tres Procesos Controladores de Disco de Bajo Nivel.
El ejemplo es bastante claro, pero también hay que decir, que como se remarca en un principio, un solo PCR puede ser SFG, si no hay otro PCR, que actúe sobre el mismo recurso. Para los PCR_AN, también hay equivalente, y se les denomina de la misma manera, y como cualquier PCR de este sistema actúan sobre un recurso, pero como ya sabemos es de tipo software. Como ejemplos podemos destacar bases de datos, filtros variados de datos, web...
Debido a su naturaleza, los SFG son puramente conceptuales, ya que no necesitan una implementación propia.
Estados de procesos.
Los procesos de cualquier tipo, no siempre tienen que estar ni activos ni funcionando, ya que puede ser, que en un momento dado no tengan trabajo que realizar, estén esperando respuesta a una petición, o se encuentre en cualquier otra situación que les haga estar inactivos.
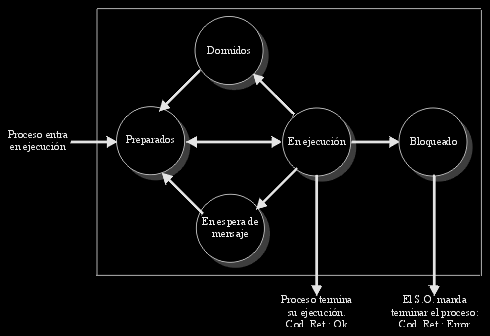
Para los procesos se definen cinco estados, que darán lugar a tres grupos de procesos durante la vida de estos mientras están bajo el auspicio del sistema operativo, estos son:
Características de los diferentes estados de procesos.
En ejecución.
En ejecución significa eso mismo, que se está ejecutando y por lo tanto está haciendo uso de la CPU. Realmente sólo un proceso puede estar en ejecución a la vez, siendo un sistema monoprocesador, ya que en un sistema multiproceso, aunque parezca que se están ejecutando una serie de procesos a la vez, realmente están accediendo de manera concurrente a la CPU, generalmente multiplexados en el tiempo.
Este proceso es el único que en un momento dado es "dueño" de la CPU, y puede acceder directamente a los servicios de la máquina mediante los PCR. El tiempo que el proceso está en ejecución, será tan largo como el tiempo que tiene asignado para ello.
Un proceso en ejecución puede volver una vez terminado su tiempo de ejecución al grupo de preparados (en la que estaba antes de empezar a ejecutarse), puede ir al grupo de dormidos, o se puede quedar bloqueado.
Proceso Preparado.
Es aquel proceso que puede empezar a ejecutarse en cualquier momento, porque está dispuesto para ello. Generalmente estarán agrupados en una cola, y se ejecutarán de una forma secuencial, según una planificación establecida por los diseñadores del sistema. Estos procesos consumen pueden consumir recurso de tiempo de ejecución de la máquina, además de los recursos consumidos de otros tipos para llevar a cabo su función, aunque no de forma inmediata, ya que tienen que llegar al estado de En Ejecución.
En un momento dado pueden pasar al grupo de dormidos, o bien terminar su ejecución, dejando por lo tanto de estar en el sistema. Para que un proceso llegue al estado de preparado, hay dos caminos, uno que comience su ejecución, con lo cual por defecto se va a ejecutarse parte de su código, o bien en segundo caso, que lleve ya un tiempo en el sistema, y estando dormido, le llegue una señal que lo active de nuevo.
Proceso en Espera.
Es aquel proceso que no puede empezar a ejecutarse de una manera inmediata una vez dentro del sistema, ya sea por que está en ciclo de espera, esperando recibir una señal, una respuesta a una petición de recurso o simplemente no tiene nada que hacer. El primer ejemplo puede darse en una sincronización entre procesos para un acceso concurrente a una posición de memoria... el segundo y más normal será el de hacer una petición de cualquier tipo al sistema y si esta implica una respuesta crítica, el proceso quedará En Espera hasta que le llegue dicha respuesta y por último, un PCR puede quedarse en espera, si no tiene peticiones que atender.
Estados posibles y transiciones de procesos.
Los procesos en espera pueden pasar al grupo de preparados, pero no pueden bloquearse ni acabar su ejecución mientras están en espera, por sí mismos, pero sí por una señal externa. Para llegar al estado de en espera, hay que pasar previamente por el estado de preparado o En Ejecución, aunque sólo sea una vez, ya que no es el estado por defecto cuando entra al sistema.
Proceso Dormido.
Prácticamente igual al estado anterior, En Espera, con la salvedad de que la espera se trata de una pausa obligada, y depende estrictamente de un temporizador, el cual se programará cuando entre en estado dormido el proceso y cuando se cumpla el tiempo de pausa indicado, se encargará de mandar una señal al proceso para que despierte.
Las pautas de entrada y salida del sistema, son equivalentes a las descritas en los procesos En Espera.
Proceso Bloqueado.
Son aquellos procesos, que por una mala lógica o defecto de programación, no responden a las llamadas del sistema y pueden ser perjudiciales para el buen funcionamiento y rendimiento general tanto del sistema operativo como para los demás procesos. No se engloban con otros procesos, ya que se puede decir que están dentro de una estado de error, y para sacar estos procesos del sistema es necesaria la ayuda del sistema operativo.
La entrada en estado bloqueado, prácticamente significa la terminación de la ejecución de su secuencia de código de una manera anormal, y su salida del sistema, en cuanto el sistema operativo tenga notificación de su situación.
Agrupamiento de estados.
Los tres grupos citados al principio de esta sección, y que corresponden a estados generales de procesos son los siguientes:
En pleno funcionamiento.
Corresponde al estado en ejecución del proceso, como se sabe este es el único estado en el que el proceso se está ejecutando, ya que es el único momento en el que consume el recurso CPU.
En espera correcta.
Agrupa los estados Preparado, En Espera y Dormido. Las características de estos modos son que están esperando una señal externa o una marca de sincronización para activarse y pasar al estado de en pleno funcionamiento. Mientras los procesos están activos en alguno de los estados de éste grupo se les supone un correcto funcionamiento y que están preparados para ejecutarse cuando se cumplan las condiciones necesarias, hasta que llegue a su fin de ejecución.
En espera incorrecta.
Corresponde al estado de bloqueado, y supone que cuando un proceso llega a este punto, ha dejado de funcionar de una manera correcta por las causas que hayan acaecido. Un proceso bloqueado, no debería de entrar a la CPU, ya que el resultado de su ejecución sería pernicioso. Cuando un proceso llega a este estado y es detectado, el proceso planificador de tareas, debería ser el encargado de descargarlo del sistema para evitar las posibles inconsistencias que éste pudiera provocar.
Convenio de llamadas a PCR.
Los PCR, administran como ya sabemos un dispositivo, pero también sabemos que varios dispositivos que controlan un mismo tipo de dispositivo, se llaman SFG. Para que haya coherencia a la hora de llamar a los SFG, los diferentes PCR que lo formen deben de soportar las mismas llamadas, para hacer transparente el uso al usuario final de las aplicaciones. Es por ello, que habrá una serie de llamadas definidas por convenio al SFG, las cuales deberán soportar todo los PCR que englobe.
Obviamente, es posible que un sistema de tratamiento de un recurso, de más facilidades que otro, y por tanto estas se tienen que poder implementar, para sacar un mayor rendimiento al sistema. Es por ello que a parte de las llamadas soportadas obligatoriamente por cada PCR, pueden tener una serie de nuevas llamadas específicas de ese módulo.
Vamos a poner un ejemplo. Tenemos por ejemplo un SFG de impresión, y tenemos dos impresoras diferentes, una puede utilizar el uso de fuentes propias y la otra no. El SFG de impresión, tendrá una serie de llamadas muy generales, y que por lo tanto van a soportar todas las impresoras, pero el PCR de la impresora más avanzada, en su implementación puede tener llamadas a cambio de fuente, cosa que el PCR de la otra impresora, más sencilla, no incluye ya que no está dentro de sus funciones.
Las funciones básicas de los SFG, los deben de imponer los diseñadores del sistema operativo, y ello convertirse en un estándar. Sin embargo las llamadas especiales, o propias de los dispositivos implementadas en los PCR, serán impuestas los el equipo que desarrolle el PCR, pero deberían de quedar suficientemente documentadas, para poder crear la mayor compatibilidad posible entre codificadores de PCR.
Proceso Planificador de Tareas (PPT).
El PPT por así decirlo, es el motor del S.O., y por lo tanto tiene que ser, un proceso muy óptimo a la hora de codificar, con el fin de que sea muy rápido y muy funcional, además debe estar totalmente libre de errores, ya que si éste, es inestable, todo el S.O. lo será.
Las tareas asignadas al PPT, son muy específicas, una es la temporización de procesos y otra el cambio de tareas. Con respecta a la primera función, lo que debe hacer es asignar un tiempo máximo de ejecución a las tareas cuyo estado es preparado. Este tiempo asignado, puede ser asignado dinámicamente cuando se trata de un sistema con un reparto de tiempo basado en prioridades, o en cualquier otra característica que lo queramos basar. La segunda función asignada, es la del cambio de tarea. Tiene que sacar de la CPU al proceso en ejecución para llevarlo al grupo de preparados o dormidos, si no se ha quedado bloqueado, o bien avisarlo para que lo haga el mismo.
El tiempo de ejecución de cada cuanto de código, vendrá dado, por una serie de parámetros definidos por las personas que hagan el desarrollo, puede venir dado por prioridad, ocupación de la CPU, número de procesos preparados... y la manera de hallar este tiempo sería mediante una tablas anteriormente cuantificadas, apoyándose en una serie de análisis estadísticos para obtener un mejor rendimiento en las diferentes situaciones planteadas, o bien dinámicamente, mediante un algoritmo de planificación.
Diagrama de jerarquía de procesos.
Ahora que ya hemos visto, los tipos de procesos existentes y las cualidades que les caracterizan, los podemos jerarquizar, en un diagrama típico de anillos, en el cual se puede ver de una manera muy gráfica, como transcurrirá el flujo de información a través de la funcionalidad del S.O. Este gráfico no requiere más comentario que, si ha quedado claro lo anteriormente expuesto no habrá problemas en su comprensión.
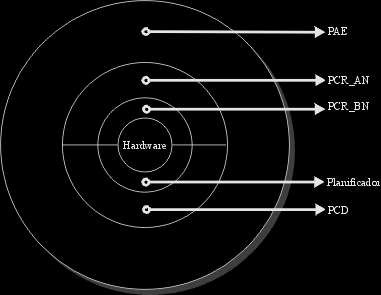
Diagrama de anillos explicativo de la jerarquía de los procesos.
A continuación vamos a ver un gráfico de capas en el que se puede apreciar como discurre el flujo de datos entre las diferentes capas. Como los PCD tienen una aplicación muy específica, y pueden realizar tareas bien diferentes, en el gráfico hemos optado por asignarle una función de mensajería. El gráfico resultante pues es el siguiente:
Modelización de un proceso.
A la hora de implementar un Proceso Estándar Zeus (PEZ) vamos a distinguir tres partes básicas bien diferenciadas.
Pasamos a detallar estas partes:
Gestor de eventos.
Este módulo de aplicación será de uso e implementación obligados, ya que va a ser el corazón de la aplicación, de hecho la vida del proceso está íntimamente ligada a la vida del gestor de eventos. Cuando se crea el gestor de eventos comienza la aplicación, y cuando acaba el gestor de eventos, se da por terminada la aplicación.
Al codificar el gestor de eventos en una programación orientada a objetos, debemos de tener en cuenta que la clase Gestor_de_Eventos, debe de ser la más básica, y que a partir de ella se irán superponiendo capas hasta crear el proceso.
Las funciones básicas del gestor de eventos son hacer una gestión avanzada de la comunicación entre procesos, con otras palabras, de ordenar respecto a una serie de criterios establecidos de ante mano, y dependientes del evento producido, los mensajes que le puedan llegar de otros procesos. Los criterios de ordenación serán impuestos por el grupo de trabajo que diseñe el módulo o gestor al que corresponda la aplicación.
Si bien como decimos las pautas de funcionamiento de éste gestor son impuestas por el grupo de diseño, deberá también de atender a un criterio básico a seguir por todos, que será el siguiente: gestionar los mensajes de liberar recursos antes que mensajes de petición de éstos. Esta regla se impone con el fin de conservar el sistema, en el sentido de poder atender la mayoría de las peticiones de recursos, teniendo en cuenta que éstos son limitados y además compartidos por la configuración del sistema. Si fueran ilimitados, no tendría por qué regirse el sistema por esta regla.
Un proceso puede tener una vida larga y provechosa para él o para el sistema, disponiendo únicamente de un gestor de eventos, de hecho un PCR, cuya función, como ya sabemos, es dedicarse a atender las posibles llamadas que le lleguen de otros procesos, con tener codificado solamente un gestor de eventos puede realizar las funciones que se le encomiendan a la perfección.
Con respecto al ámbito de comunicación, hay que decir que el gestor de eventos trata los mensajes de entrada al proceso, por lo tanto hace una función de buzón avanzado. Con respecto a la comunicación de salida, mandará los mensajes propios de acceso al sistema que sean necesarios para desenvolverse en el entorno.
Para los PAE, que no hagan un uso intensivo del gestor de eventos, se debe plantear uno generalizado y optimizado, que sea de uso general para las diferentes aplicaciones que lo necesiten, y que lo deben integrar de forma obligatoria. La definición de este gestor de eventos generalizado, debe ser impuesta por los codificadores de compiladores, que le asignarán una serie de funciones que serán debidamente documentadas para el posterior uso de los usuarios programadores de aplicaciones.
Código de aplicación.
El código de aplicación, será, y siguiendo con la metodología prevista orientada a objetos, una capa superior al gestor de eventos, que por otra parte será heredado. Esta capa es opcional ya que puede ser, que una aplicación no tenga código que ejecutar propiamente dicho, si bien y como ha quedado claro antes, ejemplo de PCB, se ejecuta el código perteneciente al gestor de eventos.
La implementación es totalmente dependiente del grupo o persona que diseñe la aplicación.
Tratando el ámbito de comunicación, hay que decir que los posibles mensaje de entrada que reciba, serán obtenidos a través del gestor de eventos, que previamente los habrá tratado respecto a las pautas establecidas, ya nombradas. Como siempre la comunicación de salida atenderá a las llamadas al sistema necesarias para su correcto funcionamiento.
El final del código de aplicación no implica el final de la vida proceso, y para que se lleve a cabo el fin de aplicación, hay que indicárselo al gestor de eventos, por las causas previamente descritas. Esta señalización puede ser generada por el compilador, pero hay que tenerla en cuenta si se trabaja a bajo nivel.
El código de aplicación no se ejecutará de manera inmediata en el cambio de contexto a la aplicación. Previamente y en primer lugar se habrá ejecutado el gestor de eventos, que evaluará la constancia o no de nuevas comunicaciones, y llevará a cabo, si procede su tratamiento, tras lo cual se empezará a ejecutar el código de la aplicación.
Interfaz de aplicación.
El espacio de interfaz de aplicación es el estamento más alto dentro de la jerarquía interna del proceso, así como el código de aplicación, es totalmente opcional. Hay aplicaciones que no se pueden concebir sin un espacio de interfaz de usuario, pero hay otras, de mantenimiento del sistema o procesos por lotes por ejemplo, que no le hace falta una interfaz propia.
Entendemos por interfaz, a una E/S vía teclado / monitor, que será definida por el diseñador de la aplicación.
En cada momento habrá una pantalla y un teclado activo que dependerá de una aplicación, en ese momento se dice que esa pantalla y teclado activos están en el foco. Foco, pues, será el punto de E/S activo de aplicaciones en un determinado momento. Hay que decir también que si bien el foco es dependiente de la aplicación, nos lo suministrará el PCR_BN de, teclado y vídeo activo en ese momento.
Así como puede ser que ciertos procesos no necesiten de un espacio de interfaz de E/S, otros pueden necesitar varias.
Estos espacios de interfaz tendrán un lugar de memoria reservado, en la cual se irán almacenando las E/S, que tengan resultado en el transcurrir de la aplicación. En el momento de que el foco sea ocupado por una aplicación, se volcará la memoria creada para E/S a los periféricos necesarios, ya sea monitor o teclado. Este sería el transcurrir de una aplicación normal y funcionando correctamente. En el caso de mensajes de errores por ejemplo, de procesos importantes como pueden ser PCR_BN o procesos en general que no tengan asignada una interfaz, se puede pasar por alto la utilización de estos espacios de interfaz, y mandar directamente la comunicación al medio físico, como por ejemplo puede ser la memoria de vídeo, siempre y cuando se de la opción de hacer un retrazado de pantalla, para poder eliminar los mensajes que hayan aparecido en pantalla, y que una vez se ha dado por enterado el usuario, ya no tienen ningún interés y molesten para el trabajo.
|
Flujos de información |
¿Qué son los flujos de información?
Como ya sabemos, cualquier información que discurre de manera física por el interior de nuestro ordenador, son una serie de señales eléctricas, que se rigen por una serie de convenios y normas, para dar un significado intrínseco a su existencia.
Al más bajo nivel de tratamiento de la información, nos encontramos con esta serie de señales eléctricas, que para nosotros es difícil que tengan un significado propio a primera vista. Sin embargo para el ordenador, y por ser su naturaleza eléctrica es lo único que entiende.
El sistema operativo se ve en la difícil posición de convertir las señales eléctricas provenientes de los periféricos, en información que sea legible por el usuario. El camino inverso también es tratado por el sistema operativo, es decir, transformar el lenguaje que comprenden las personas en el lenguaje propio de la máquina, todo ello con el fin de administrar los diferentes recursos de la máquina, y de hacer del uso de la misma, algo útil para el usuario o consumidor.
Estas series de señales eléctricas en sí, ya son flujos de información. Generalmente estos flujos transcurren de un periférico a otro a través de los buses de la máquina, siendo su transcurrir totalmente transparente al usuario cuando todo funciona de una manera correcta.
Estos flujos de información pueden pertenecer a dos tipos de datos bien diferenciados:
Flujos de control.
Flujo de control es aquel, que no tiene un contenido de valor específico para el usuario de alto nivel, o consumidor final, pero sí, y muy importante, para el periférico, ya que de ello depende su funcionamiento correcto, dentro de las pautas establecidas para su uso.
Así pues la información que posee este tipo de flujo es básica y primordial, para el buen funcionamiento del sistema, ya que se pueden encargar de inicializar, activar, desactivar, comprobar estado... de los diferentes periféricos que podemos utilizar. Cada periférico para ello, tendrá una serie de registros en los cuales, leeremos, o escribiremos, una serie de señales, dándonos respuesta de sus estado, o proporcionándole una nueva pauta de funcionamiento. Vemos pues que las señales de control también, y como todo en el mundo informático, tienen un sentido de entrada y/o salida.
Flujos de datos.
Flujo de datos es aquel que acarrea una información cuyo contenido puede ser útil para el usuario, y que también discurre de periférico a periférico.
La información que transcurre de este tipo por los buses, puede ser de las más diferentes naturalezas, y con los cometidos más diferentes, pero no por ello dejan de ser señales eléctricas.
Para el usuario final, esta información es importante, que es lo que quiere visualizar en el monitor, guardar en un disco, recuperar información de otro disco, escuchar música de un CD por los altavoces del ordenador...
De la misma manera, y valga el ejemplo anteriormente expuesto del almacenamiento en disco, los flujos de entrada también pueden ser de entrada y/o salida, dependiendo obviamente del origen y su destino.
Conclusión.
La conclusión de esta pequeña introducción al movimiento de datos, es que, el ordenador sólo puede tratar señales eléctricas, el ser humano, no puede tratar de una manera natural dichas señales, y sin embargo, tiene que haber un método de comunicación entre máquina – humano, que haga provechoso el uso del ordenador.
Para ello, hay que llegar a un nivel de abstracción, que haga posible dicha comunicación. El nivel de abstracción llega de mano de la lógica, que trata las señales eléctricas como 0 y 1, dependiendo de su nivel eléctrico.
De todos los modos el uso del código binario, no resulta ni muy intuitivo ni muy cómodo para el ser humano. Es por ello, que se agrupan pequeñas secuencias de bits, así llamados dichos 0 y 1, en una serie de caracteres que pueden transmitir información legible por el ser humano.
¿Que es un mensaje?.
El mensaje es la unidad mínima de intercomunicación de procesos. Las funciones del mensaje son amplias y variadas, pero se pueden restringir a dos grandes tipos de grupos de intercambio de información:
Petición y atención de recursos del sistema (Mensaje normalizado).
Este tipo de mensaje, por así decirlo es la columna vertebral del sistema, ya que será el que se encargue, de llevar las peticiones de recursos -de una manera estructurada y con formato predeterminado- desde un proceso, hasta el servidor que se lo administra. Así mismo mediante el mensaje, se devolverá la información necesaria en forma de estructura normalizada, si es requerida, en respuesta a la solicitud. Este tipo de mensaje pues es el que realmente haga funcionar el sistema.
En principio este modo de mensajería funcionaría basándose una arquitectura cliente servidor, cuyos extremos serían, el proceso solicitante, y el administrador del recurso, pero a lo largo de la vida del sistema operativo, se pueden crear servidores que no administren recursos de tipo físico (como pueden ser bases de datos, web...) con los cuales, también se podría establecer una comunicación de este tipo
Traspaso de información sin formato entre procesos (Mensaje no normalizado).
Este grupo de mensajería, es necesario para llevar una comunicación no formalizada, entre procesos. Este mensaje, sin llegar a ser, se podría definir como un canal de comunicación abierto, para transmitir cualquier tipo de dato.
Sin más que indicar sobre el tema terminamos el apartado de teoría del Sistema Operativo ZEUS 98.
![]()
Última actualización de la página: 12/03/99
Esta página está hospedada en ![]() Consigue tu Página
Web Gratis
Consigue tu Página
Web Gratis
